🗓️ Fecha: 10 de abril de 2025
👤 Autor: Jose Alexis Correa Valencia
🔗 LinkedIn
📌 Objetivo del Modelo
El modelo físico de IRIS representa la estructura relacional definitiva que será implementada en un motor de base de datos (por ejemplo, MySQL o PostgreSQL), para soportar las funcionalidades del sistema de análisis oftalmológico con inteligencia artificial.
Incluye:
- Entidades físicas (tablas)
- Tipos de datos precisos
- Claves primarias y foráneas
- Campos de auditoría y trazabilidad
📘 Descripción de Tablas y Estructura de Campos
🧍♂️ user
Contiene los datos de los usuarios del sistema (administradores, operadores, etc.).
| Campo | Tipo | Descripción |
|---|---|---|
| user | VARCHAR(13) | Identificador único (PK) |
| username | VARCHAR(255) | Nombre de usuario |
| role | VARCHAR(50) | Rol del usuario |
| VARCHAR(255) | Correo electrónico | |
| password | VARCHAR(255) | Contraseña encriptada |
| status | VARCHAR(50) | Estado (activo/inactivo) |
| author | VARCHAR(13) | Usuario que creó este registro (FK) |
| created_at | DATETIME | Fecha de creación del registro |
| updated_at | DATETIME | Última actualización |
| deleted_at | DATETIME | Eliminación lógica |
🧑⚕️ professional
Representa a los profesionales de la salud (oftalmólogos principalmente).
| Campo | Tipo | Descripción |
|---|---|---|
| professional | VARCHAR(13) | Identificador único (PK) |
| username | VARCHAR(255) | Nombre de usuario |
| specialty | VARCHAR(100) | Especialidad médica |
| VARCHAR(255) | Correo electrónico | |
| password | VARCHAR(255) | Contraseña encriptada |
| status | VARCHAR(50) | Estado del profesional |
| author | VARCHAR(13) | Usuario que lo registró (FK) |
| created_at | DATETIME | Creación del registro |
| updated_at | DATETIME | Última modificación |
| deleted_at | DATETIME | Eliminación lógica |
👁️ patient
Tabla de pacientes con sus datos personales y de contacto.
| Campo | Tipo | Descripción |
|---|---|---|
| patient | VARCHAR(13) | Identificador único (PK) |
| first_name | VARCHAR(100) | Nombres |
| last_name | VARCHAR(100) | Apellidos |
| document_type | VARCHAR(50) | Tipo de documento |
| document_number | VARCHAR(50) | Número de documento |
| birth_date | DATE | Fecha de nacimiento |
| gender | VARCHAR(20) | Género |
| contact_info | TEXT | Teléfono, correo u otro contacto |
| registration_date | DATE | Fecha de registro |
| author | VARCHAR(13) | Usuario creador (FK) |
| created_at | DATETIME | Fecha de creación |
| updated_at | DATETIME | Última modificación |
| deleted_at | DATETIME | Eliminación lógica |
📋 episode
Representa un episodio clínico dentro de la atención al paciente.
| Campo | Tipo | Descripción |
|---|---|---|
| episode | VARCHAR(13) | Identificador único (PK) |
| patient | VARCHAR(13) | Referencia al paciente (FK) |
| start_date | DATE | Fecha de inicio del episodio |
| end_date | DATE | Fecha de finalización |
| reason_for_visit | VARCHAR(255) | Motivo de consulta |
| general_notes | TEXT | Observaciones generales |
| author | VARCHAR(13) | Usuario que creó el episodio (FK) |
| created_at | DATETIME | Creación del episodio |
| updated_at | DATETIME | Modificación |
| deleted_at | DATETIME | Eliminación lógica |
🔬 study
Cada estudio representa un conjunto de imágenes capturadas en una sola sesión diagnóstica.
| Campo | Tipo | Descripción |
|---|---|---|
| study | VARCHAR(13) | Identificador del estudio (PK) |
| episode | VARCHAR(13) | Episodio al que pertenece (FK) |
| study_date | DATE | Fecha del estudio |
| study_type | VARCHAR(100) | Tipo de estudio (OCT, retinografía) |
| status | VARCHAR(50) | Estado (pendiente, completado) |
| observations | TEXT | Observaciones generales |
| author | VARCHAR(13) | Usuario que creó el estudio (FK) |
| created_at | DATETIME | Creación del registro |
| updated_at | DATETIME | Modificación |
| deleted_at | DATETIME | Eliminación lógica |
🖼️ image
Almacena los detalles de cada imagen retiniana.
| Campo | Tipo | Descripción |
|---|---|---|
| image | VARCHAR(13) | ID único de imagen (PK) |
| study | VARCHAR(13) | Estudio al que pertenece (FK) |
| capture_date | DATE | Fecha de captura |
| eye | VARCHAR(20) | Ojo izquierdo/derecho |
| image_file | VARCHAR(255) | Ruta o nombre del archivo |
| image_quality | VARCHAR(100) | Calidad de imagen |
| operator_comments | TEXT | Notas del operador |
| author | VARCHAR(13) | Usuario que la cargó (FK) |
| created_at | DATETIME | Fecha de creación |
| updated_at | DATETIME | Última modificación |
| deleted_at | DATETIME | Eliminación lógica |
🤖 ai_report
Resultado del análisis automático por inteligencia artificial.
| Campo | Tipo | Descripción |
|---|---|---|
| ai_report | VARCHAR(13) | ID del informe (PK) |
| image | VARCHAR(13) | Imagen analizada (FK) |
| analysis_date | DATE | Fecha del análisis |
| ai_results | TEXT | Resultado del análisis IA |
| confidence_score | FLOAT | Nivel de certeza del análisis |
| ai_recommendations | TEXT | Sugerencias automáticas |
| author | VARCHAR(13) | Usuario que ejecutó (FK) |
| created_at | DATETIME | Fecha de creación |
| updated_at | DATETIME | Modificación |
| deleted_at | DATETIME | Eliminación lógica |
📝 report
Informe final validado por el profesional de salud.
| Campo | Tipo | Descripción |
|---|---|---|
| report | VARCHAR(13) | ID único del informe (PK) |
| study | VARCHAR(13) | Estudio evaluado (FK) |
| professional | VARCHAR(13) | Profesional que valida (FK) |
| validation_date | DATE | Fecha de validación |
| final_diagnosis | TEXT | Diagnóstico final |
| observations | TEXT | Observaciones clínicas |
| is_validated | BOOLEAN | Validación confirmada o pendiente |
| author | VARCHAR(13) | Usuario que creó el informe (FK) |
| created_at | DATETIME | Creación del informe |
| updated_at | DATETIME | Modificación |
| deleted_at | DATETIME | Eliminación lógica |
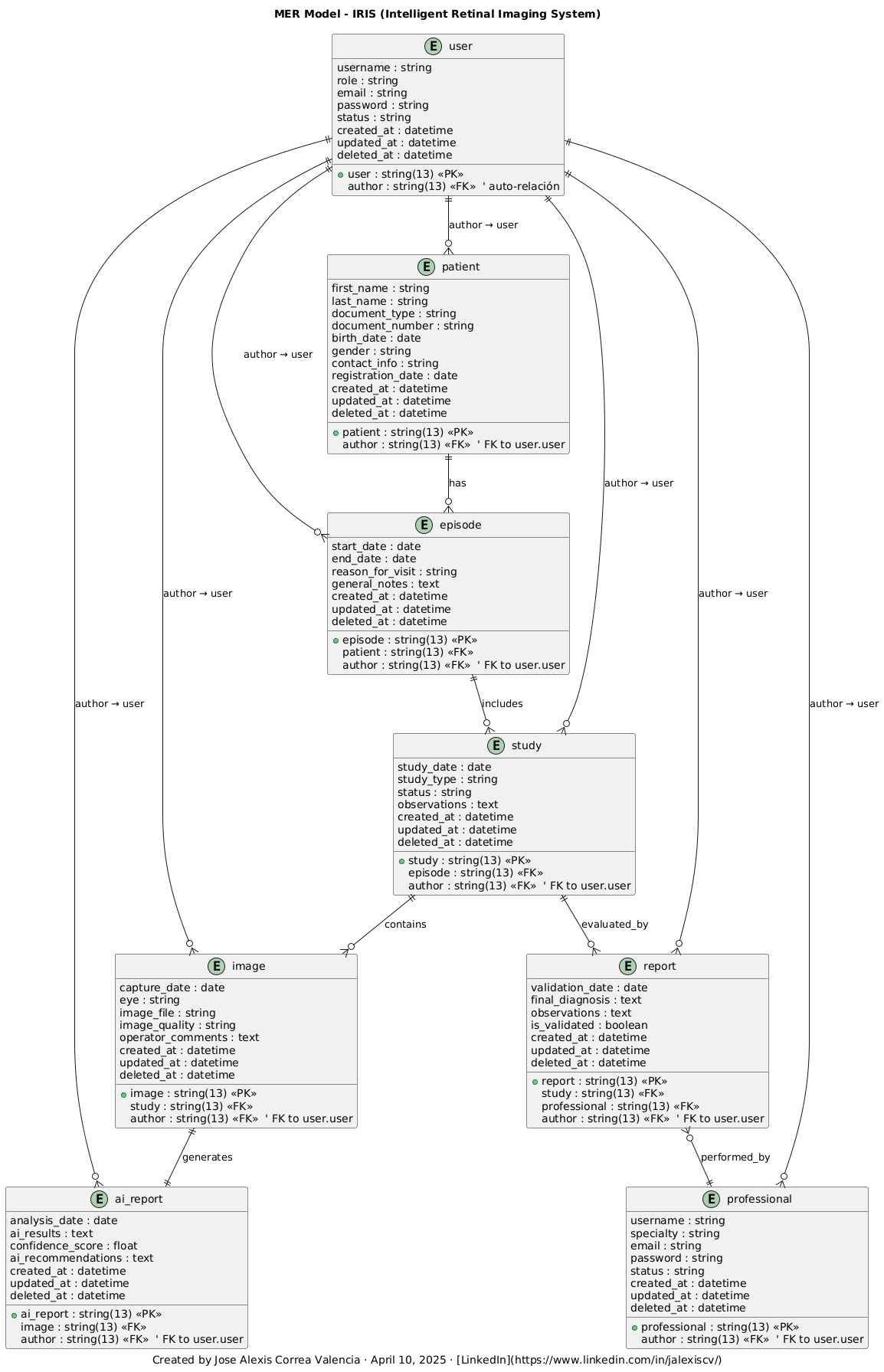
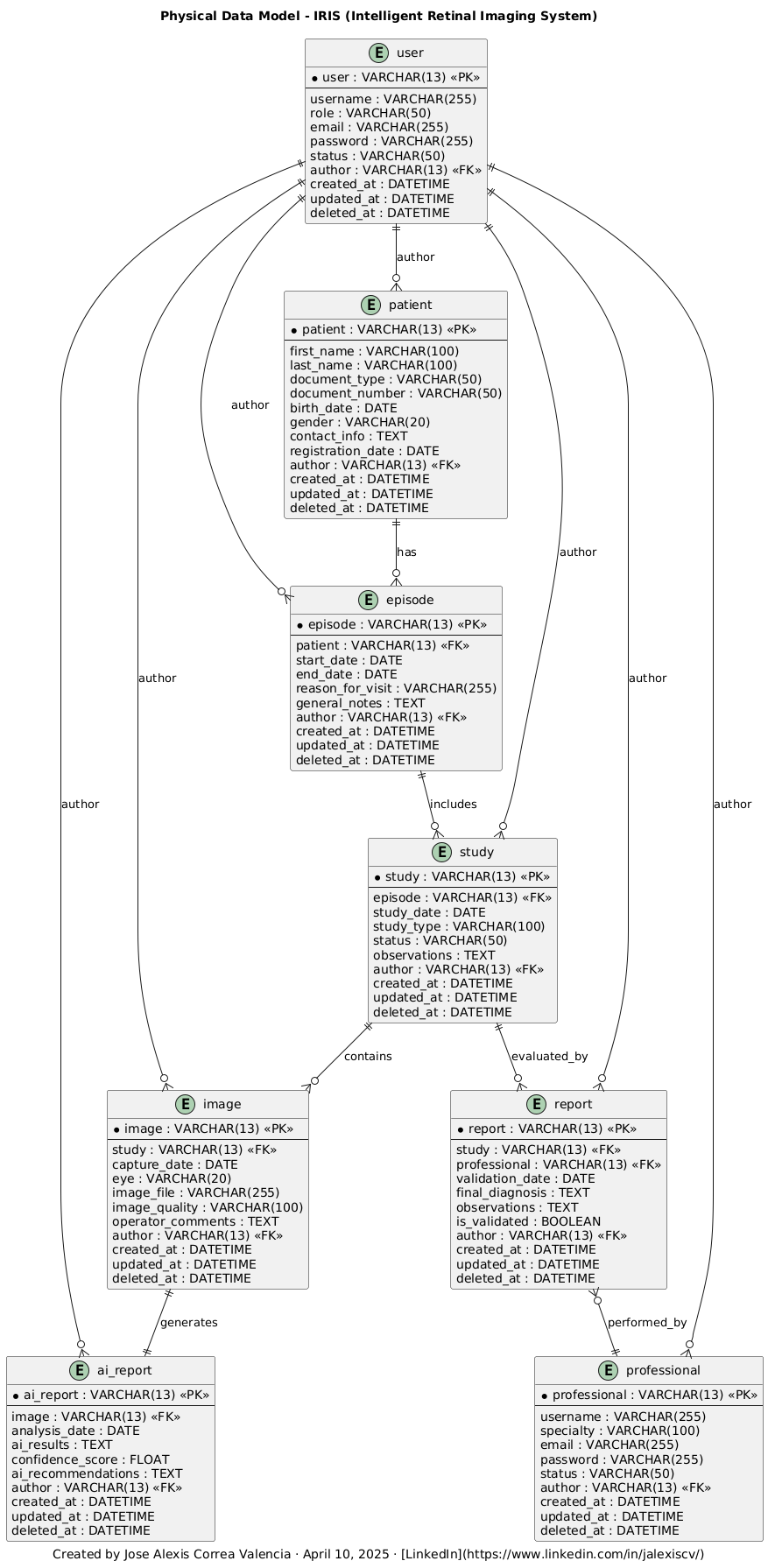
🔗 Claves Foráneas y Relaciones
- Todas las entidades contienen un campo
authorque referencia auser(user)como trazabilidad. - Relaciones clínicas:
patient→episodeepisode→studystudy→image,reportimage→ai_reportreport→professional
Código SQL
CREATE TABLE user (
user VARCHAR(13) PRIMARY KEY,
username VARCHAR(255),
role VARCHAR(50),
email VARCHAR(255),
password VARCHAR(255),
status VARCHAR(50),
author VARCHAR(13),
created_at DATETIME,
updated_at DATETIME,
deleted_at DATETIME
);
CREATE TABLE patient (
patient VARCHAR(13) PRIMARY KEY,
first_name VARCHAR(100),
last_name VARCHAR(100),
document_type VARCHAR(50),
document_number VARCHAR(50),
birth_date DATE,
gender VARCHAR(20),
contact_info TEXT,
registration_date DATE,
author VARCHAR(13),
created_at DATETIME,
updated_at DATETIME,
deleted_at DATETIME
);
CREATE TABLE episode (
episode VARCHAR(13) PRIMARY KEY,
patient VARCHAR(13),
start_date DATE,
end_date DATE,
reason_for_visit VARCHAR(255),
general_notes TEXT,
author VARCHAR(13),
created_at DATETIME,
updated_at DATETIME,
deleted_at DATETIME
);
CREATE TABLE study (
study VARCHAR(13) PRIMARY KEY,
episode VARCHAR(13),
study_date DATE,
study_type VARCHAR(100),
status VARCHAR(50),
observations TEXT,
author VARCHAR(13),
created_at DATETIME,
updated_at DATETIME,
deleted_at DATETIME
);
CREATE TABLE image (
image VARCHAR(13) PRIMARY KEY,
study VARCHAR(13),
capture_date DATE,
eye VARCHAR(20),
image_file VARCHAR(255),
image_quality VARCHAR(100),
operator_comments TEXT,
author VARCHAR(13),
created_at DATETIME,
updated_at DATETIME,
deleted_at DATETIME
);
CREATE TABLE ai_report (
ai_report VARCHAR(13) PRIMARY KEY,
image VARCHAR(13),
analysis_date DATE,
ai_results TEXT,
confidence_score FLOAT,
ai_recommendations TEXT,
author VARCHAR(13),
created_at DATETIME,
updated_at DATETIME,
deleted_at DATETIME
);
CREATE TABLE report (
report VARCHAR(13) PRIMARY KEY,
study VARCHAR(13),
professional VARCHAR(13),
validation_date DATE,
final_diagnosis TEXT,
observations TEXT,
is_validated BOOLEAN,
author VARCHAR(13),
created_at DATETIME,
updated_at DATETIME,
deleted_at DATETIME
);
CREATE TABLE professional (
professional VARCHAR(13) PRIMARY KEY,
username VARCHAR(255),
specialty VARCHAR(100),
email VARCHAR(255),
password VARCHAR(255),
status VARCHAR(50),
author VARCHAR(13),
created_at DATETIME,
updated_at DATETIME,
deleted_at DATETIME
);
-- Add foreign key constraints
ALTER TABLE patient ADD FOREIGN KEY (author) REFERENCES user(user);
ALTER TABLE episode ADD FOREIGN KEY (patient) REFERENCES patient(patient);
ALTER TABLE episode ADD FOREIGN KEY (author) REFERENCES user(user);
ALTER TABLE study ADD FOREIGN KEY (episode) REFERENCES episode(episode);
ALTER TABLE study ADD FOREIGN KEY (author) REFERENCES user(user);
ALTER TABLE image ADD FOREIGN KEY (study) REFERENCES study(study);
ALTER TABLE image ADD FOREIGN KEY (author) REFERENCES user(user);
ALTER TABLE ai_report ADD FOREIGN KEY (image) REFERENCES image(image);
ALTER TABLE ai_report ADD FOREIGN KEY (author) REFERENCES user(user);
ALTER TABLE report ADD FOREIGN KEY (study) REFERENCES study(study);
ALTER TABLE report ADD FOREIGN KEY (professional) REFERENCES professional(professional);
ALTER TABLE report ADD FOREIGN KEY (author) REFERENCES user(user);
ALTER TABLE professional ADD FOREIGN KEY (author) REFERENCES user(user);Código UML
@startuml
title Physical Data Model - IRIS (Intelligent Retinal Imaging System)
caption Created by Jose Alexis Correa Valencia · April 10, 2025 · [LinkedIn](https://www.linkedin.com/in/jalexiscv/)
entity user {
*user : VARCHAR(13) <<PK>>
--
username : VARCHAR(255)
role : VARCHAR(50)
email : VARCHAR(255)
password : VARCHAR(255)
status : VARCHAR(50)
author : VARCHAR(13) <<FK>>
created_at : DATETIME
updated_at : DATETIME
deleted_at : DATETIME
}
entity patient {
*patient : VARCHAR(13) <<PK>>
--
first_name : VARCHAR(100)
last_name : VARCHAR(100)
document_type : VARCHAR(50)
document_number : VARCHAR(50)
birth_date : DATE
gender : VARCHAR(20)
contact_info : TEXT
registration_date : DATE
author : VARCHAR(13) <<FK>>
created_at : DATETIME
updated_at : DATETIME
deleted_at : DATETIME
}
entity episode {
*episode : VARCHAR(13) <<PK>>
--
patient : VARCHAR(13) <<FK>>
start_date : DATE
end_date : DATE
reason_for_visit : VARCHAR(255)
general_notes : TEXT
author : VARCHAR(13) <<FK>>
created_at : DATETIME
updated_at : DATETIME
deleted_at : DATETIME
}
entity study {
*study : VARCHAR(13) <<PK>>
--
episode : VARCHAR(13) <<FK>>
study_date : DATE
study_type : VARCHAR(100)
status : VARCHAR(50)
observations : TEXT
author : VARCHAR(13) <<FK>>
created_at : DATETIME
updated_at : DATETIME
deleted_at : DATETIME
}
entity image {
*image : VARCHAR(13) <<PK>>
--
study : VARCHAR(13) <<FK>>
capture_date : DATE
eye : VARCHAR(20)
image_file : VARCHAR(255)
image_quality : VARCHAR(100)
operator_comments : TEXT
author : VARCHAR(13) <<FK>>
created_at : DATETIME
updated_at : DATETIME
deleted_at : DATETIME
}
entity ai_report {
*ai_report : VARCHAR(13) <<PK>>
--
image : VARCHAR(13) <<FK>>
analysis_date : DATE
ai_results : TEXT
confidence_score : FLOAT
ai_recommendations : TEXT
author : VARCHAR(13) <<FK>>
created_at : DATETIME
updated_at : DATETIME
deleted_at : DATETIME
}
entity report {
*report : VARCHAR(13) <<PK>>
--
study : VARCHAR(13) <<FK>>
professional : VARCHAR(13) <<FK>>
validation_date : DATE
final_diagnosis : TEXT
observations : TEXT
is_validated : BOOLEAN
author : VARCHAR(13) <<FK>>
created_at : DATETIME
updated_at : DATETIME
deleted_at : DATETIME
}
entity professional {
*professional : VARCHAR(13) <<PK>>
--
username : VARCHAR(255)
specialty : VARCHAR(100)
email : VARCHAR(255)
password : VARCHAR(255)
status : VARCHAR(50)
author : VARCHAR(13) <<FK>>
created_at : DATETIME
updated_at : DATETIME
deleted_at : DATETIME
}
' Relaciones de autoría
user ||--o{ patient : "author"
user ||--o{ episode : "author"
user ||--o{ study : "author"
user ||--o{ image : "author"
user ||--o{ ai_report : "author"
user ||--o{ report : "author"
user ||--o{ professional : "author"
' Relaciones clínicas
patient ||--o{ episode : "has"
episode ||--o{ study : "includes"
study ||--o{ image : "contains"
image ||--|| ai_report : "generates"
study ||--o{ report : "evaluated_by"
report }o--|| professional : "performed_by"
@enduml